출처: 이기용 교수님, 데이터마이닝및분석 수업
7장에서는 클러스터링이 무엇인지와 대표적인 클러스터링인 (1) K-means, (2) Agglomerative Hierarchical Clustering, (3) DBScan에 대해서 배웠다.
이번에 정리한 내용은 클러스터링이 무엇인지에 대한 내용이다.
순서대로 전반적으로 정리하자면,
- 클러스터링이 무엇인지: 유사한 값끼리 그룹이 나뉘어지는 것. 하지만 이 '유사함'에 있어 사용자가 직접 정의해야하고, 어떻게 유사도를 정의할 것인지가 중요한 이슈.
- 클러스터링의 목적은 무엇인지: Understandig, Utility
- 좋은 클러스터링이란? 같은 그룹내에서는 유사하고, 다른 그룹과는 차이가 최대화 되어야한다.
- Classification, Segmentation, Partitioning 과의 차이: Classification은 지도학습
- Clusterings의 종류: Partitional vs Hierarchical, Exclusvie vs Overlapping vs Fuzzy, Complete vs Partial
- Cluster의 종류: Prototype-based, Density-based, Graph-based
이런 순서대로 전개된다.
Cluster Analysis (Clustering)
- Clustering 은 data를 ‘유사한’ 값끼리 groups(clusters) 으로 나눈다.
- 어떤 데이터가 ‘유사한지’는 사용자가 직접 정해야 하는 것이고, 이에 따라 클러스터링 결과가 달라지기 때문에 데이터의 유사도를 어떻게 정의할 것인지가 중요한 이슈.
- Clustering 은 다양한 field에서 중요한 역할을 한다(사용 범위가 넓다).
심리학 및 기타 사회과학, 생물학, 통계, 패턴 인식, 정보 검색, 기계 학습 및 데이터 마이닝 등
- Clustering의 목적은 아래 두 가지, Understanding 과 Utility로 나뉜다.
Clustering for Understanding
: data의 natural structure를 파악하기 위해 클러스터링을 사용한다 → 나한테 주어진 데이터를 이해하고자 할 때
: potential classes (clusters)를 자동으로 찾는 것이 목표이다. → 공통점을 공유하는 개념적으로 의미 있는 개체 그룹
Application examples
– 생물학: 유사한 기능을 가진 유전자 그룹 찾기
– 정보 검색: 검색 결과(웹 페이지)를 카테고리로 그룹화 (ex. 쿼리 "movie"의 검색 결과 → 리뷰, 트레일러, 평점 ... )
– 기후: 기압과 해양 온도의 패턴 찾기
– 심리학 : 다양한 유형의 우울증을 식별하기
– 의학: 질병의 공간적/시간적 분포에서 패턴을 감지하기
– 비즈니스: 고객을 소수의 그룹으로 분할하기
Clustering for Utility
: data size의 크기를 줄이기 위해 클러스터링을 사용한다 → 주어진 데이터를 활용하려고 할 때
: 가장 대표적인(representatvie) cluster prototypes를 찾는 것이 목표이다. → cluster 내 객체를 대표하는 data 객체를 찾아내는 것이다.
Application examples
(1) Summarization(요약)
- 전체 데이터 세트를 cluster prototype으로만 구성된 데이터 세트로 축소 → 데이터 분석의 시간 또는 공간 복잡성을 줄일 수 있다
- 점들을 깨알같이 저장하는 것이 아니라 (반지름, 중심)을 기준으로 알 수 있다
(2) Compression(압축)
- 각 cluster prototype에 정수 value(indx) 할당 → cluster와 연결된 prototype의 index로 각 개체를 표시한다
- 각각의 점에 가까운 cluster 번호를 저장하면, 원본 데이터 특성을 유지하면서 데이터를 대폭 줄일 수 있다
(3) 가장 가까운 이웃을 효율적으로 찾기
- 가장 가까운 이웃을 찾으려면 모든 점 사이의 거리를 계산한다 → 대신 가장 가까운 prototype 을 찾고 해당 cluster의 점만 고려한다
- k-NN 처럼 모든 데이터의 거리를 측정한 후에 가장 가까운 k개를 찾는 경우, 모든 데이터를 보는 것은 overhead가 크기 때문에 가장 가까운 cluster만 보고 거기에 속한 애들과만 거리를 재면 된다.
What is Cluster Analysis?
: object(개체)와 해당 relationship(관계)를 설명하는 데이터에서만 발견된 정보를 기반으로 data objects를 그룹화한다.
목표
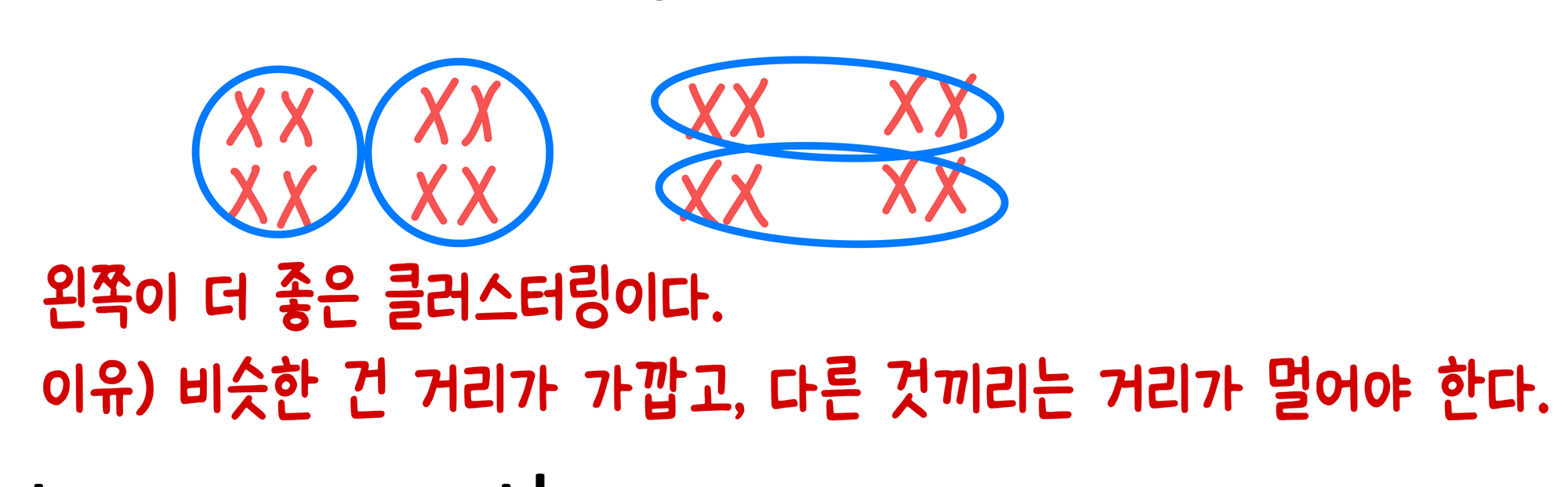
- 그룹 내의 objects가 서로 유사(similar)하다
- 그룹의 objects가 다른 그룹의 objects와 다르다(different)
이 두 조건이 모두 만족되어야 한다.
따라서, 좋은 클러스터링을 정의하자면,
좋은 클러스터링이란?
- 그룹 내 유사성을 최대화한다. (maximizes the similarity within a group)
- 그룹 간의 차이를 최대화한다. (maximizes the difference between groups)
Classificiation vs Clustering
- classification: supervised learning(지도학습) → 데이터들이 어떤 class인지 알려줌
- clustering: unsupervised learning (비지도 학습) → 데이터 어떤 class인지 아무도 알려주지 않고, 같은 그룹의 애들을 분류하는 것
Difficulty in Clustering
: clustering의 개념이 애매하고 + 주관적 → clustering 알고리즘 종류가 많다.
: 많은 applications에서 cluster의 개념이 확실히 정의되지 않았다. → cluster의 정의가 imprecise(부정확)하다.
: 최적의 정의는 nature of data와 desired results에 따라 달려있다.

Classification vs Clustering
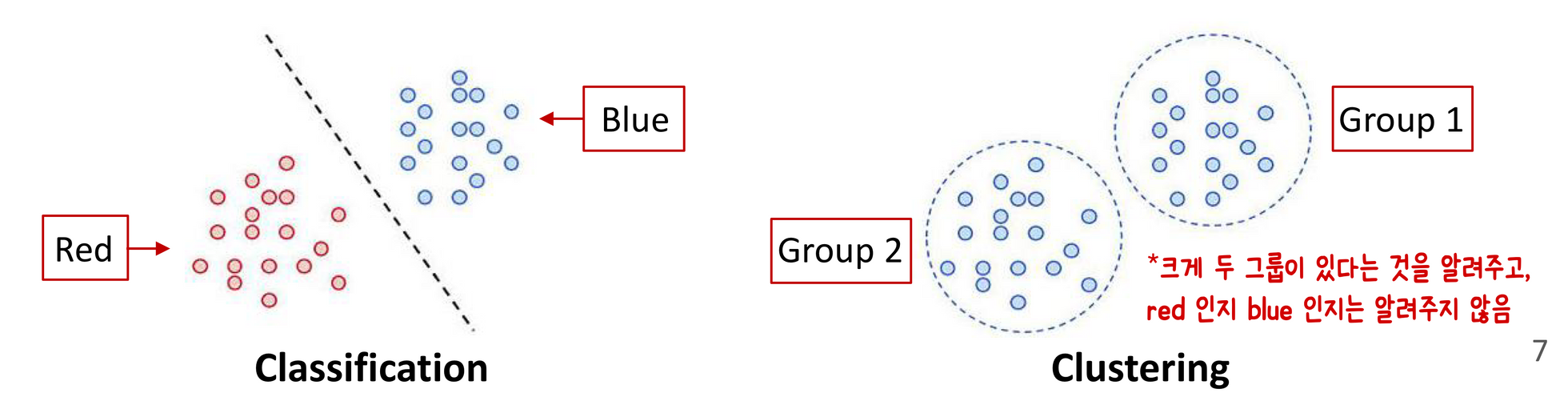
- clustering은 class(cluster) label이 있는 개체의 label을 생성한다는 점에서 classification 의 한 종류라고 할 수 있다.
- Classification → supervised classification (일반적인 사용)
– 알려진 class label이 있는 객체에서 개발된 모델을 사용하여 label이 없는 새로운 객체에 class label이 할당된다. - Clustering → unsupervised classification
– 이러한 label은 data에서만 파생된다.
Segmentation, Partitioning vs Clustering
: segmentation, partitioning 은 clustering의 동의어(synonyms)로도 사용된다.
: 기존 cluster 분석 이외의 접근 방식에 자주 사용된다.
Partitioning : 사용자가 분할 기준을 지정하는 것.
- ex) ‘나이’를 20살 이상/미만으로 나누어라, 데이터를 월별로 나눠라
- 특정 기준에 따라 데이터를 나누고 clustering 과 강하게 연결되지 않은 기술과 관련하여 자주 사용된다.
- clustering은 알아서 유사한 값들을 모아주지만, partitioning 은 사용자가 미세할지라도 ‘기준’을 세워줘야 한다.
Segmentation
- 종종 간단한 기법을 사용하여 data를 group으로 나누는 것
- ex) 영상은 픽셀 강도와 색상만을 기준으로 세그먼트로 분할할 수 있다(이미지 분류 시),
사람들을 그들의 소득에 따라 그룹으로 나눌 수 있다(유사 고객끼리 분류 시)
Different Types of Clusterings
(1) Partitional Clustering vs Hierarchical Clustering
: 대부분은 Partitional clustering 인지 Hierarchical clustering 인지 나눌 수 O

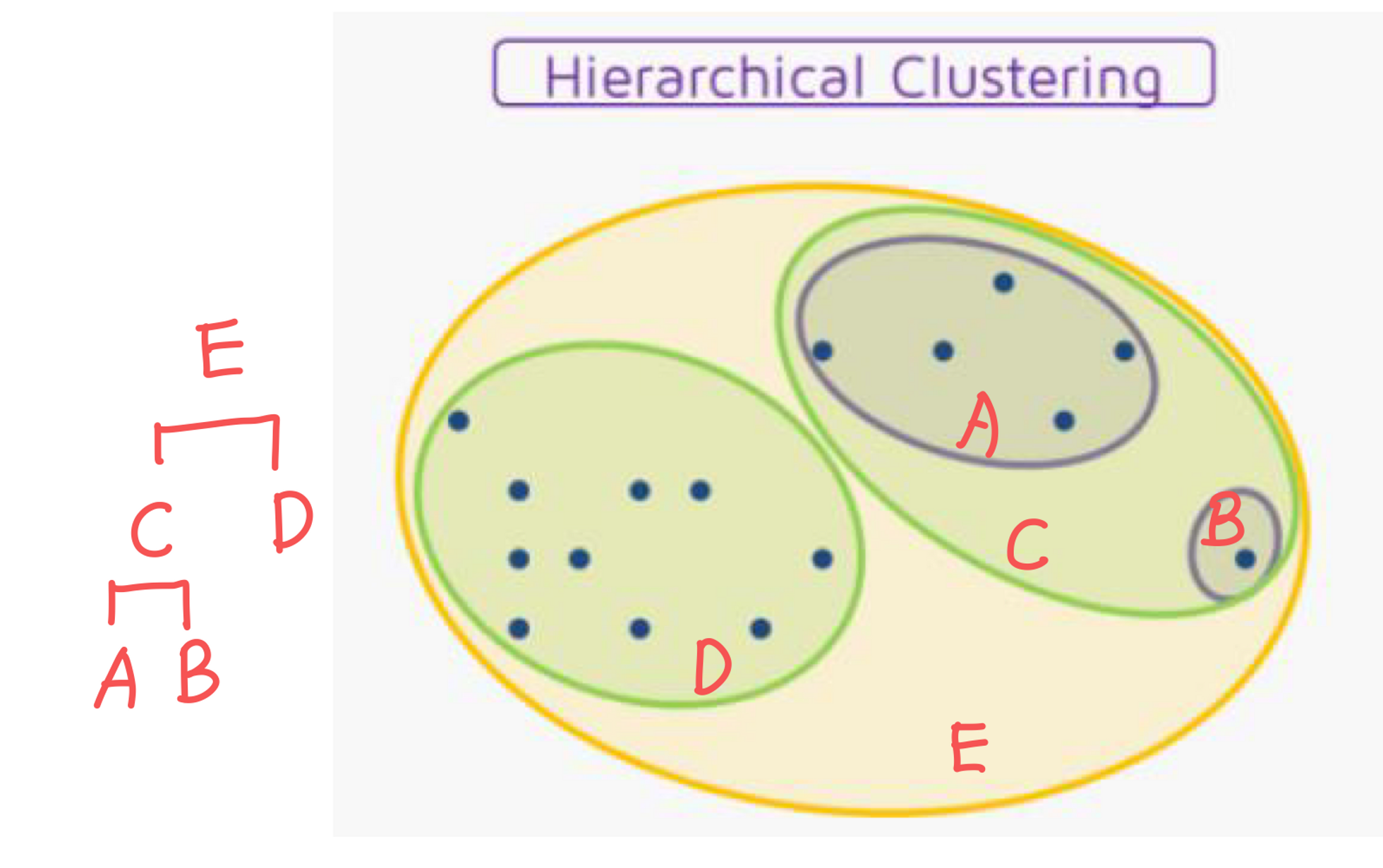
(1-1) Partitional clustering
: set of data objects를 non-overlapping(중복되지 않는) subsets (clusters)으로 분할하여 각 data object가 정확히 하나의 subsets 에 있도록 합니다
: 계층이 없다.
ex) k-means
(1-2) Hierarchical clustering
: tree로 구성된 nested(중첩된) clusters 집합
: tree의 각 node(cluster)는 그것의 children cluster(sub cluster)의 union이고 tree의 root는 모든 개체를 포함하는 cluster이다
: 가능한 모든 조합을 뽑은 후에 detail한 값을 찾아가는 것. clusters의 개수를 control 할 수 있다.
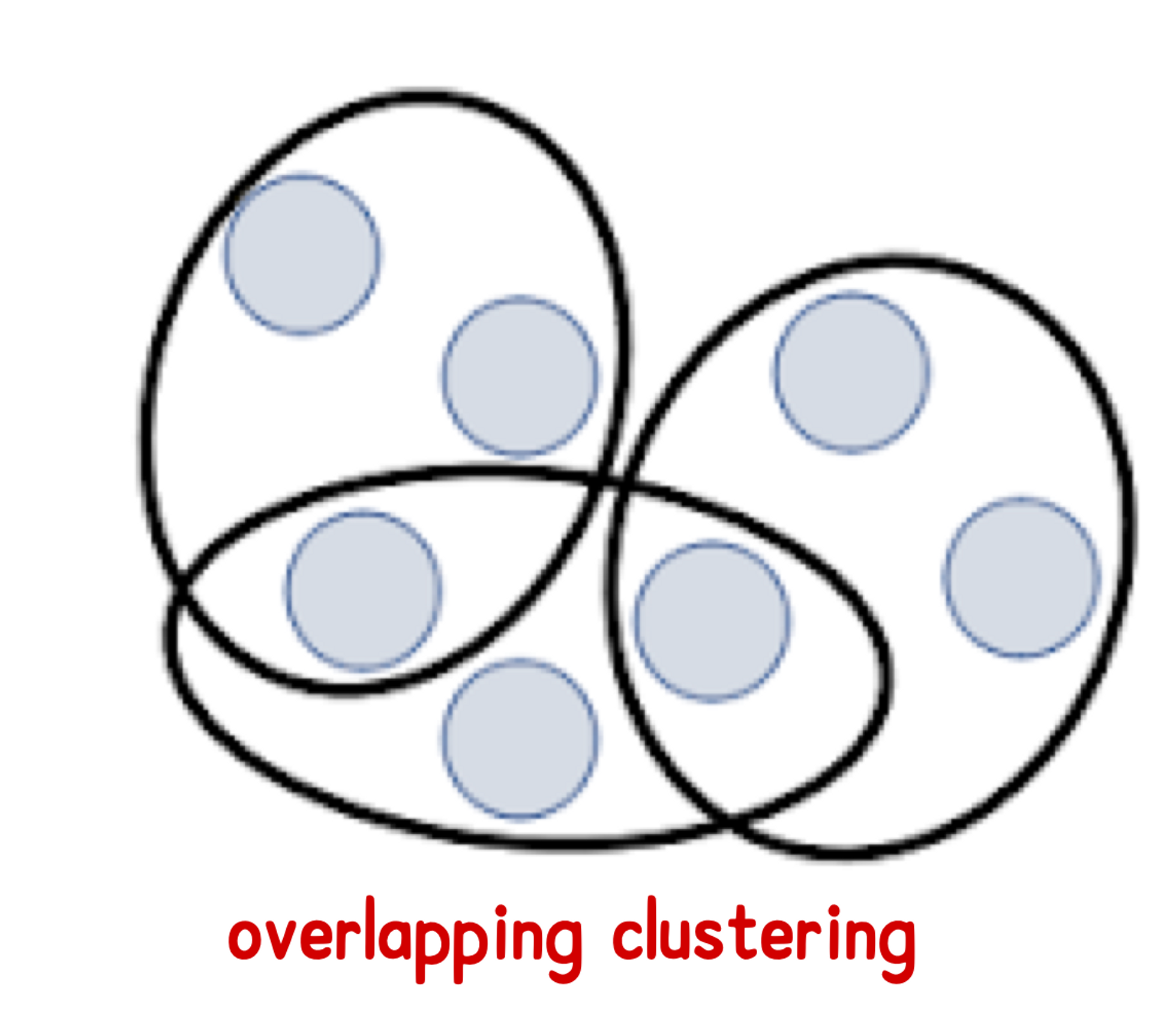
(2) Exclusive Clustering vs Overlapping (or non-exclusive) Clustering vs Fuzzy Clustering
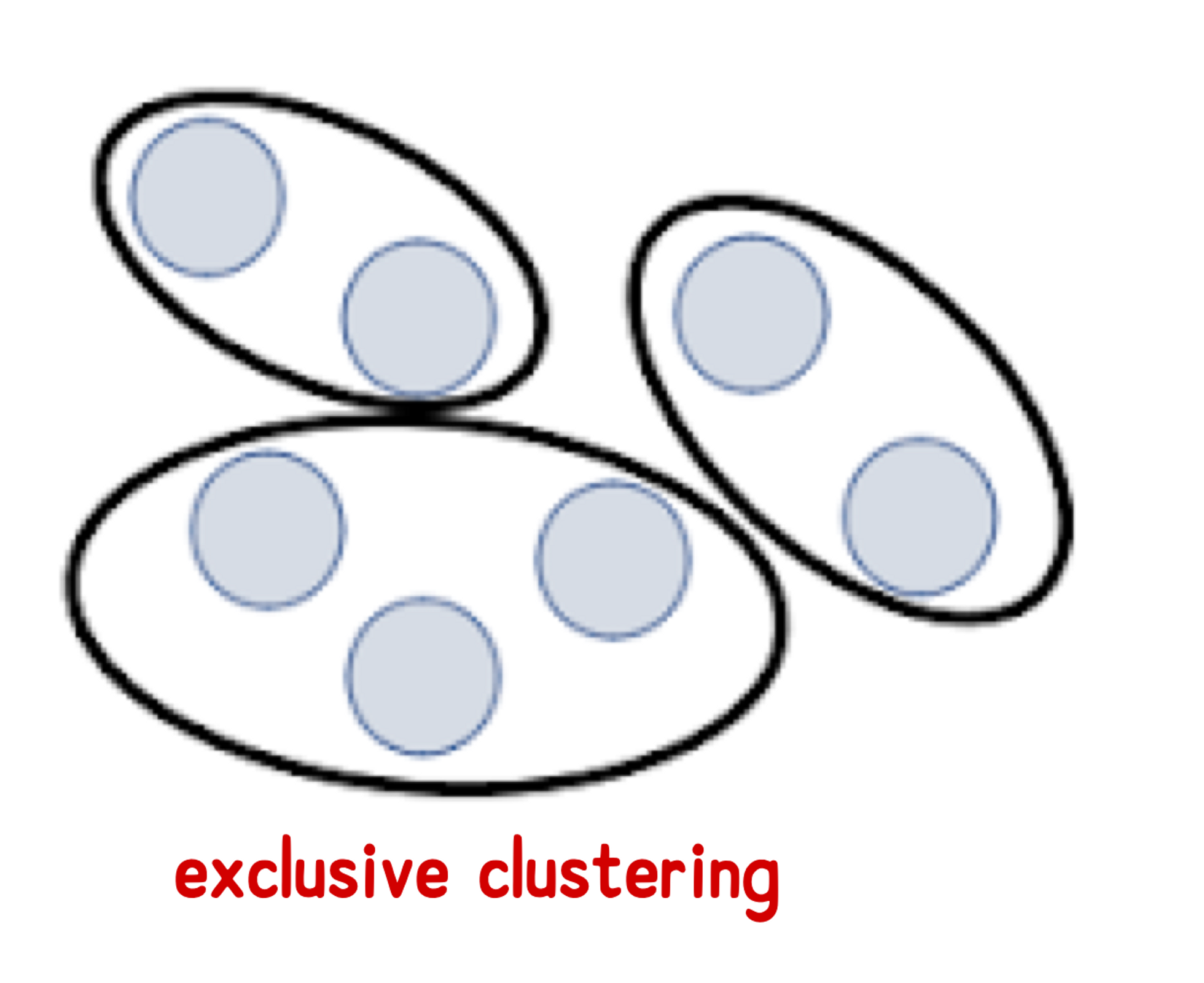
(2-1) Exclusive clustering
: 각 object가 single(단일) cluster에 할당됨 (=모든 애들은 하나의 클러스터에만 소속됨)
(2-2) Overlapping (or non-exclusive) clustering
: object는 동시에 둘 이상의 클러스터에 속할 수 있음
: 애매한 경우 하나의 객체가 여러 개의 cluster에 들어갈 수 있다.
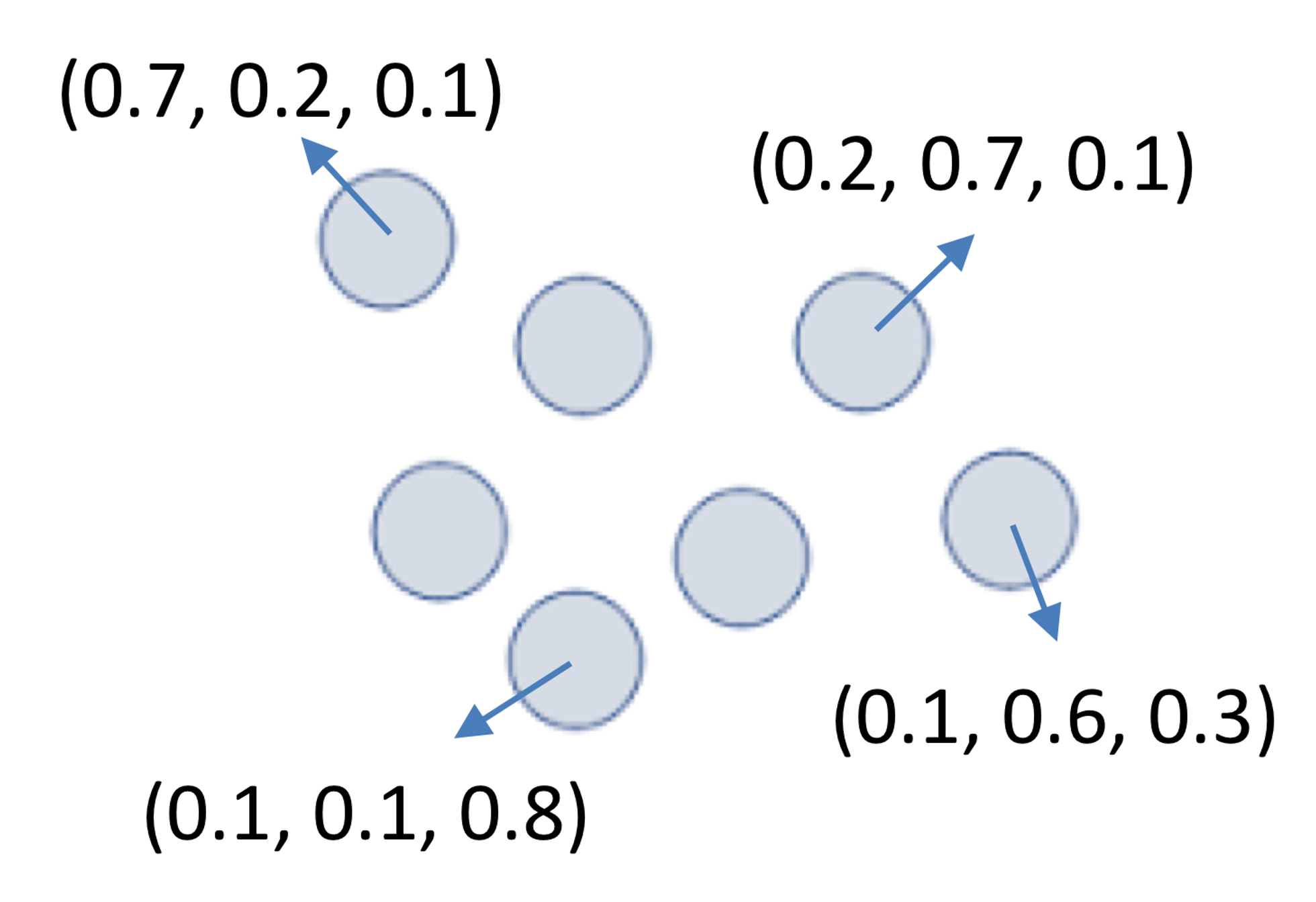
(2-3) Fuzzy clustering
: 모든 object는 membership weight 를 가진 모든 cluster에 속함
: 0(절대 소속 없음)과 1(절대 소속됨) 사이
(3) Complete clustering vs Partial clustering
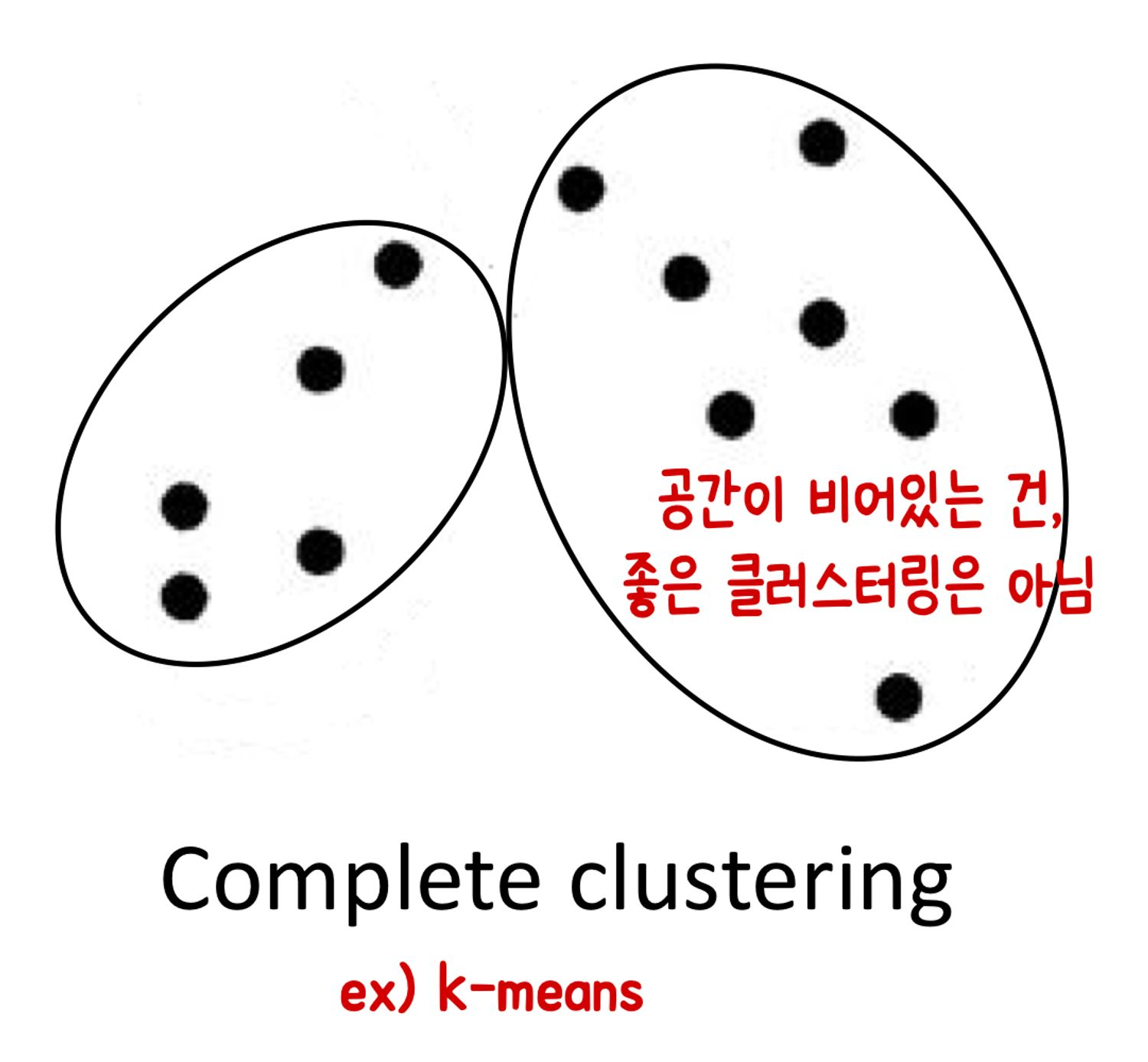
(3-1) Complete clustering
: 모든 obejct를 어떤 cluster에라도 할당
: ex) k-meas → 따라서 outlier에 취약 (어떻게든 넣으려고 하기 때문에)
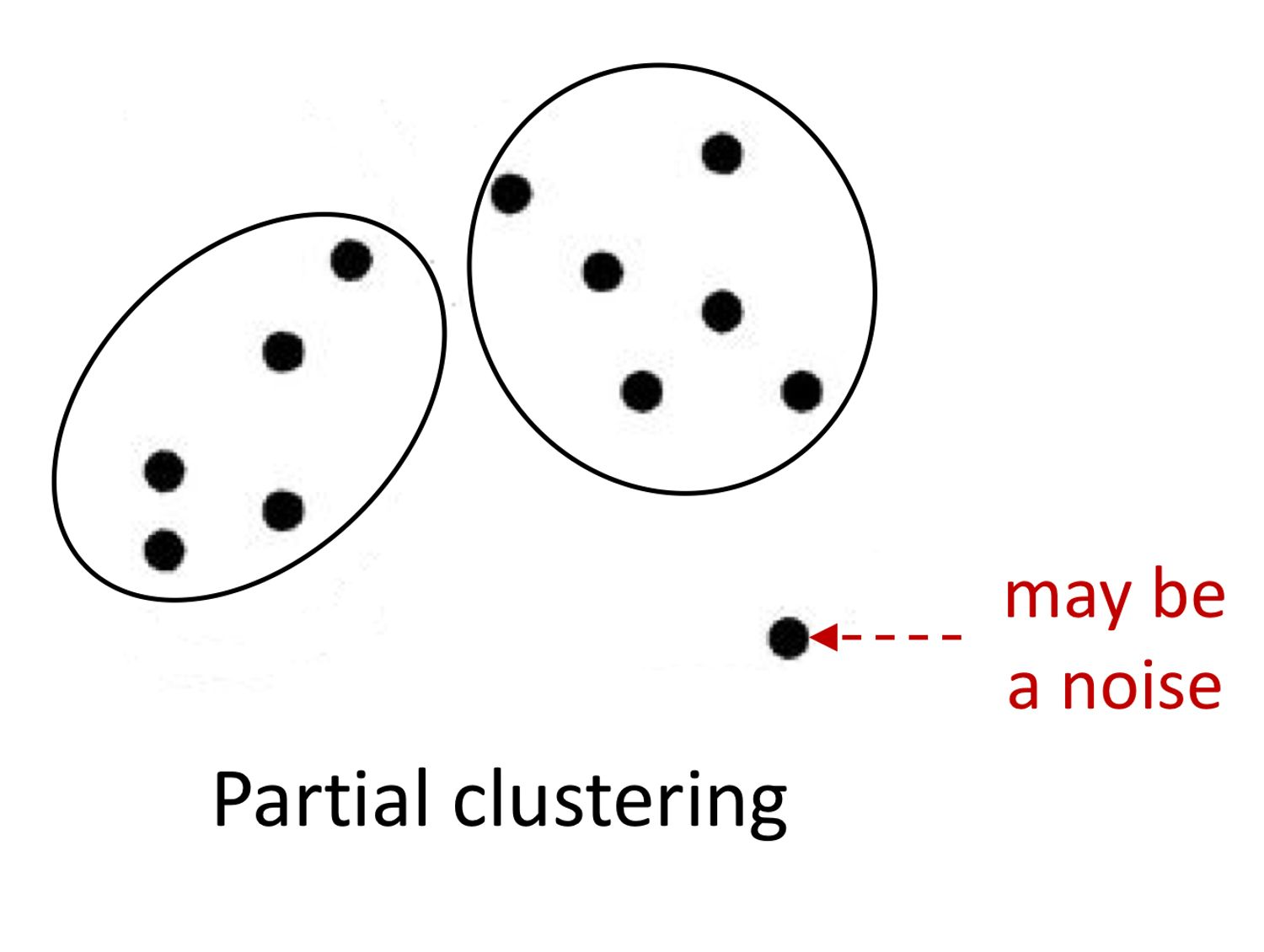
(3-2) Partial clustering
: 모든 개체를 클러스터에 할당할 필요X. 부적합하면 제외.
: 일부 objects 는 well-defined groups 에 속하지 않을 수 있다.
: (ex) noise, outliers 또는 "uninteresting background"
Different Types of Clusters
: cluster가 무엇인지에 대해서 정의하는 것도 알고리즘 마다 다르다.
Prototype-based (전형적)
- cluster는 각 개체가 다른 cluster의 prototype보다 cluster의 prototype(ex: centroid)에 더 가까운 개체 집합.
- 대표 cluster를 잡고 그 주변 애들을 모아서 cluster라고 정의 ex) k-means
Density-based (밀도)
- cluster는 objects의 low density의 지역으로 둘러싸인 dense region(빽뺵한 지역)이다.
Graph-based
- cluster는 그래프에서 connected component 이다. node는 object이고, link는 object 간의 연결.
- 주로 소셜 네트워크 분석에서 많이 쓰임 → community detection
RoadMap
: 이번 장에서 배울 대표적인 세 가지 클러스터링에 대해 미리 정리한 표이다.
| K-means | Agglomerative hierarchical clustering | DBSCAN | |
| cluster 타입 | prototype-based | prototype-based or graph-based | density-based |
| partitional vs hierarchical | partitional | hierarchical | partitional |
| partial vs complete | complete clustering | partial clustering |


